In February 2014, after moving to Manhattan and being unable to find
a New York City network for Women Who Code
(WWCode), I decided to start one. Ten months later, we have a strong NYC
network with over 1500 members. We’re
growing by 50+ members a month and have no signs of losing steam.
What has contributed to our success?
We owe much of our success to our San Francisco-based parent
organization. They made introductions to technology companies with whom
they’d already built relationships. The Women Who Code brand was also a
big advantage. Many of our members and partners already know about our
organization, and thus are more likely to want to be involved. Not
every meetup group will have a parent organization, so this is very
unique.
Another important factor was having a co-founder. Starting a meetup
group is, of course, a huge commitment. With a co-founder, we can split
a lot of the work required to organize hosts, speakers, and all the
email correspondence that comes along with starting a network.
A strong and committed membership base has been vital. Our members want
to be involved and help. Of course, organizing volunteers (we prefer to
call them event organizers) is a lot of work, and luckily my co-founder
is great at this. She quickly scouted event organizers to run our
Front-End Developer Study Group, which is a popular weekly event.
What are our biggest challenges?
Finding hosts
With up to six events a month, finding organizations to host our events
is possibly the most challenging aspect of running our meetup group.
We found the host for our first event by approaching the organizer of
another meetup group, Luke Melia of
Ember NYC. He was generous and made
several introductions to the CTOs of NYC-based companies. This helped us
get the ball rolling.
Being a part of the wider Women Who Code network has obviously helped.
We get many introductions and leads from our parent organization, our
advisor Sasha Laundy, and affiliated
networks. Our members also help us find hosts—usually their employers or
friends.
Being part of the WWCode organization combined with our large membership
means many organizations approach us to host. While we welcome this,
we tread carefully. For instance, recruiting agencies and for-profit
educational institutions often want to host us. We always give them a
shot, but we ensure our members aren’t being targeted too heavily.
Additionally, we have to be picky about space. If the wifi was
unavailable for most of the meetup or the environment was simply not
conducive to productivity, we won’t have an event there again.
Cold calling, mainly on Twitter, is something we often do. We send
tweets to CTOs, recruiters, and software engineers at various companies.
This is most successful if the organization has special diversity
initiatives. For example, the WWCode CEO alerted us to the Fog Creek
Fellowship.
We sent a tweet to a top recruiter there and quickly booked them for a
Lightning Talks event. However, we’re not always this lucky. Tweets
sometimes go unanswered and we move on.
LinkedIn has more recently proven to be an important resource. Both my
co-founder and I get lots of messages from recruiters. If the recruiter
works at a technology company (versus a recruiting agency), then we ask
if they might be interested in hosting an event for WWCode. While this
tactic has only worked 15% of the time, it’s garnered important partners
like Facebook and LinkedIn.
Finding speakers
Finding speakers is similar to finding hosts. We find speakers through
our parent organization, who often recommend potential speakers or make
introductions. We also encourage our members to speak, especially those
with interesting side projects or aspirations to become speakers. We
always invite our hosts to have someone from their organization speak.
We do our best to keep tabs on people we read about or meet at
conferences or other meetups, particular those that are NY-based. And
sometimes women approach us to speak at our events.
In addition, our hosts have been instrumental in finding speakers. For
example, last Fall we teamed up with Condé Nast for a panel called
“Finding Your Voice and Bringing Ideas to Life.”
They found the moderator and most of the panelists.
Some tips
Get to know your meetup attendees. I ask about the type of
programming they’re doing, their interests, their personal projects,
and if they have any feedback.
Find a co-founder if at all possible to share responsibilities.
Fill up your meetup calendar with events at least six months out.
This gives the impression that your group is active and helps potential
members determine if the group is right for them.
Book hosts well ahead of time. There’s nothing more stressful than
trying to find a host for an event that’s just a few days away.
Always have food at your events. Otherwise, people will arrive late
or leave early to get dinner.
Open up RSVPs about 20 days before the date of your event. We made
the mistake of allowing people to register for all of the events on
our calendar, including those six months out. These people simply
forgot about the events, resulting in lower attendance rates.
Do a head count at every event to find patterns and determine your
average attendance rate. 50% is typical for us, but it also depends
on the host. A meetup at Facebook or Fog Creek will have a higher
attendance rate than one at a lesser known organization. We also
found that our attendance rates dip in the Fall and Winter, probably
due to the colder weather and shorter days.
When approaching potential hosts, keep your email message short
and to the point. We have a standard template that includes the
requirements for hosting (space, food, and internet for 20–50 women),
a list of upcoming events that need hosts, and a sample schedule.
Starting the Women Who Code NYC network is perhaps the most rewarding
experience I’ve ever had. It’s a lot of work and while it can be
tiresome, helping women improve their programming and
tech skills is amazing. I’ve learned a lot about time management
and event organization, and have met amazing people along the way.
You're at your friend's house, chillin', maybe watching something on the
TV, when suddenly you're hit with inspiration. "OH MY GOD, THAT'S THE
PERFECT STARTUP IDEA!" you think. Visions of Sand Hill dance through
your head as you envision the world changed by your brilliant new idea
for a social network for crows, but there is one problem. You left your
computer at home. You ask to borrow your buddy's machine, but you find
it unusable. You sit there, staring blankly at a command line, filled
with gibberish.
You turn to your friend. "Uhhhh…. how do I get an editor?" A flurry of
random letters, and you're in vim. But something's wrong. DVORAK!
Has this ever happened to you? If so, you've fallen victim to someone
else's over-customized environment! But don't despair. I'm here to show
you some useful ones.
Why Customize? (or, Vanilla Bash Oughtta Be Good Enough For Everyone)
Three reasons: efficiency, comfort, and developer happiness. All three of
these come together to let you be more productive. Having an
environment that you're comfortable in, that empowers you to do things
more easily, and that removes your pain points, will help you in the
long run. A well-configured environment will give you two kinds of
efficiencies:
The first kind of efficiency is the straightforward automation
efficiency that engineers work all day to create for businesses. It's
the kind of automation talked about in one of my favourite XKCDs:
You might think it is a waste of time to customize your tools. Maybe you
think you're getting things done fast enough as it is. But you're
probably blind to just how many times you do a given thing. Even if you
shave 10 seconds a day off of your interactions with Git, how many times
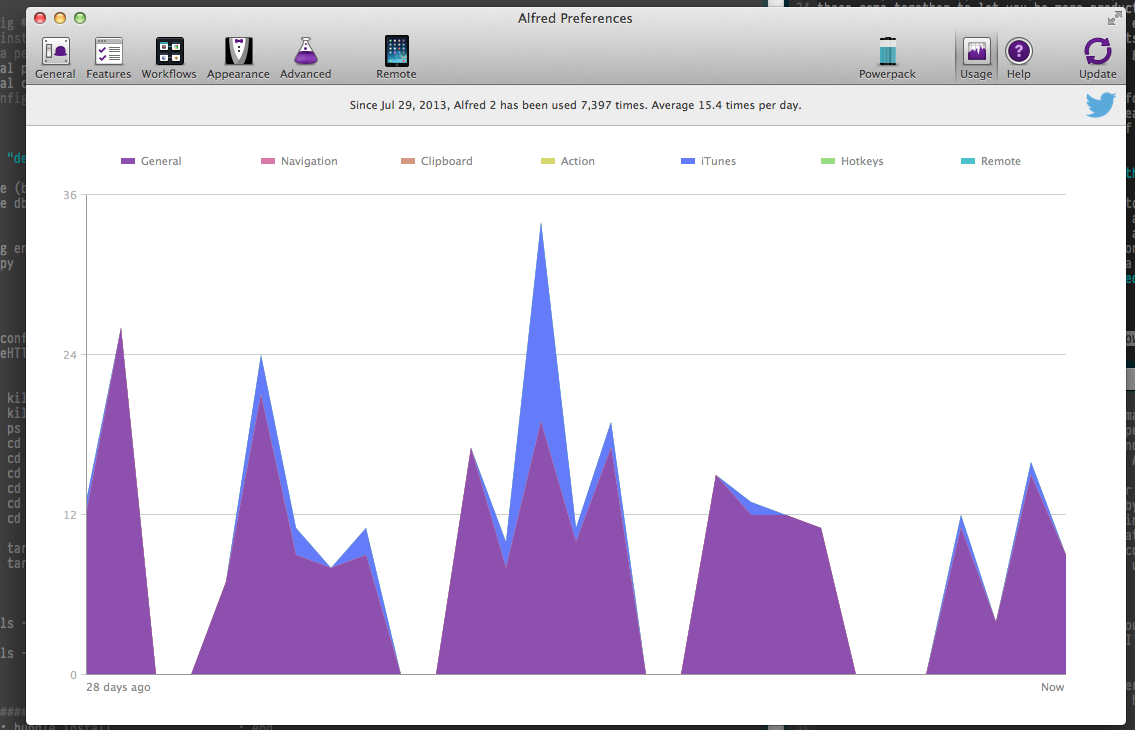
do you commit in a day? (hint: it should be a lot). Take, for example,
my usage graph from Alfred (more on this
later)
According to the XKCD graph, using Alfred 20 times a day, assuming the
smallest possible time gain (1 second), entitles me to work on it for
approximately 10 hours before I break even. Consider, then, that I've
been carrying most of these customizations with me since college, and
I've already shaved a full day off of executing programs that the rest
of you are spending clicking through Finder.
However, the second kind of efficiency is the more important one. I'm
sure that you've heard of "flow" before.
Flow is the state of
mind in which you're fully engaged on the task at hand, bringing to bear
the full might of your impression mental faculties. Flow is the
difference between killing an hour on
r/roombaww waiting for 5PM, and missing
your train because woah how'd it get to be 8PM, oh heck did I forget to
eat dinner again? Flow is where you do your best work, and as an
engineer, you should prioritize getting into it as much as possible,
every day.
One of the biggest enemies of flow is interruption. Ask most engineers
about this, and they're likely to tell you about all the ways in which
Management interrupts them and wastes their
time. But this is not
the most common interruption. The most common interruptions are the
small ones. The five- or ten-second cognitive delays you have to make in
tricky situations when you drop out of autopilot and have to think
"What's the syntax for ln
again?".
Seriously. Every single time I'm making a symlink I have to do the same
thing:
And then, I cat both foo and bar
just to make absolutely sure that they both contain "foo".
"That's right. It's source then target. I'll never forget again. Until
next week.
By customizing your environment, you can remove as many of those
potential future ln -s's out of your path right now. You can replace
long, involved commands with shorter, more automatic keystrokes. You
can make aliases for complex or often-error'd interactions. Each of
these steps may on its own seem pointless, but the sum of all the
individual optimizations is a more frictionless working environment.
Alright. Show Me What You Got
By now you should be sold on the virtues of making your environment your
own. By the time you're done with it, it should be as comfortable as
Homer Simpson's Butt Groove
But where should you start? Well, I started by borrowing from my
friend's customizations, so in the interest of paying it forward, I'll
share my l33t environment haxxz.
Unless otherwise stated, all of the following customizations are
available at my Dotfiles repo on
Github
The Command Prompt
I use a custom prompt generator for my prompt. This is primarily because
implementing it in shell script was too slow. However, this has made it
portable, and as I've moved from Bash to Zsh to Fish, this has been
helpful.
This is an example of my prompt. There is a lot of information packed
into this.
First, "source". This is the name of the current directory. It is colour
coded based on which server I'm on. I currently have it set up as
follows: Blue denotes my work machine.
Yellow is my personal laptop. Magenta is the terminal on my website, and
everything else defaults to Red. Ever
accidentally run a command on prod? I won't; I can check the colour of
the path.
The next section is git info. It begins with a nag counter. The red 2h
means it has been 2 hours since my last commit. This starts as a green 0
and slowly counts up minutes. At 30 minutes it turns yellow. Two hours,
red. Above two hours it stops displaying minutes and starts displaying
the count in hours. And above 24 hours, in days. A friendly reminder to
commit early and often.
Next, 'env-post', refers to the current branch. This will be * for
master, and otherwise the branch name. In this case, I'm on the env-post
branch of our blog repo. The branch name will be green for a clean
branch, and magenta otherwise.
Speaking of branch cleanliness, env-post is magenta. The reason is the
next few characters. They give me an at-a-glance idea of the current
branch status. The D means a file was deleted. The A means a file was
added. The ? means there are unstaged changes. And the 7 counts the
total number of changes that a git status would return.
The last element of the prompt is the %. This tells me I'm not a
superuser. If I was logged in as root, it would be a # instead. It's
green. This means the last command was successful. If it was not, it
would be red, and prefixed with the exit code from the failing command.
Shell Customizations
I use the Fish shell for my work. This is a
shell with a much friendlier working environment. On the one hand, this
means it's not encumbered by 30 years of UNIX baggage. On the other
hand, it is not Bash compatible, so I often have to debug little
issues with install scripts. In any case, I have a large number of shell
modifications , which you can find in ` .config/fish/fish.config ` in my
dotfiles repo. I'd like to highlight a few of my more common
optimizations here
Near the top, I have a 'misc' section. It has some useful commands
function def Used as % def foo, this does a full text search of the current dir and
all subdirs for a ruby method definition of the passed in method (in
this case, 'foo'). Useful to find where some code is defined
function pyserv This creates a simple http server in the current
directory, serving up the files. It has its uses, if nothing else, as an
easy way to fileshare on a local network.
function psag This runs the process list and searches it for a
given string.
the 'u' functions "cd .." is a weird way to go up one level. "cd
../../../../../.." is a weird way to go uuuuuup six levels
tarx and tarc Tar, like ln, is lost arcana, known only to the last
remaining Level 27 Unix Masters. Well, until I wrote down the most
common way to create and extract tarballs
function ls I override ls with gnu ls and several custom flags.
Without this:
With this:
Bundler and rails section
Most of these commands are shortenings of normal usage. A few stand out
function bers and function berc Rails 2 invokves commands via script/foo. Rails 3+
use rails foo. This is my attempt to harmonize both.
function rRg Ever wanted to search for a specific route? Grep the
output of rake routes
function rlc and function rlv Will grep the server output for words
that indicate controllers and views respectively. Useful for tracking
down execution in unfamiliar code
Git section
There's a lot of writing on the internet about how the basic interface
to git is mega confusing. I agree. That's why I made my own. Common
operations get their own three (or sometimes four) -letter shortcuts. My
normal workflow consists of the following:
gcom (git checkout master). gpum (git pull upstream master). gps
(git push (to my branch)). gcob WT-1234 (git checkout -b with the name
of whatever jira ticket). And so on and so on.
Finally, I have several local customizations for ssh'ing into work
machines (sorry, the details are secret). I don't type ssh
username@sillynamingconvention.12.23.32.232.blurb.com, I simply type
webteam. Takes me straight to our team's staging server.
Vim
I use Vim as my standard editor, along with Yehuda Katz'
Janus framework. I don't use the
majority of the extensions (I don't even know what they are!) but I'm
slowly learning them. Most of them are commonsense things that I would
go looking for anyway. Check it out for details!
Alfred
I mentioned above, I use a launcher program called Alfred
to manage most of my gui workflows. At first glance, it looks like
nothing more than a replacement for OSX's spotlight, but it is much,
much more. I don't even use it to the full extent; I mainly use it for
invoking programs, switching windows, and controlling my music. A simple
tap on ⌘-space brings up the Alfred window, where I can type a few
characters and it will intelligently fuzzy-match it to recently used
commands.
I also use it to control my music. By typing 'it' I activate the itunes
client, which lets me do a bunch of things, most with a single text
command
Alfred comes with a visual scripting environment that lets you make all
kinds of custom control scripts. Maybe some day I'll make some of them.
For example, I've a friend who has Alfred scripts to control his Rails
development environments. It's saved him oodles of time!
Chrome
What kind of web developer would I be if I didn't have Chrome
customizations? I've only a few, and they're only useful in niches, but
dang if this job doesn't have a ton of niches.
I often need to interact with and debug APIs, but Curl forever eludes
me. So I got this instead. It's a pretty straightforward REST request
manager. It lets you set headers with a convenient form, specify HTTP
verbs, save requests for later. It's pretty useful
This extension gives you a button that, once clicked, will highlight
every html element with events bound to it, and show you the javascript
that will run on a given event trigger when you mouse over the
highlights. This is super useful for JS heavy applications.
Search Shortcut Abuse
One final technique I've come across is abusing search shortcuts.
Nominally a search shortcut is just that: say I type "wikipedia" in the
url bar, that tells the browser to search wikipedia with whatever else
I type. But how does it do this? By crafting the correct query URL on
wikipedia. For instance, searching Google for "test" really just means
navigating to http://google.com/search?q=test. Using this lets me abuse
this functionality on other sites. For instance, I have every repo at
work set up to let me effortlessly search for a commit on github. If I
type <repo> <sha> it will expand to http://<internal
git>/therd/<repo>/commit/<sha>, showing me the commit I want. I've set
up a similar tool for Jira tickets.
Closing thoughts
You should customize your environment. Customizing your environment can
speed up common tasks. It can encapsulate complexity into simple things
that don't break your concentration. It can provide new functionality
that you can make into a core part of your workflow.
If nothing else, it stops coworkers from borrowing your machine :D
Tim is a Software Engineer on the Web Team. He's spent entirely too
much time customizing his development environments, and hiding cat
pictures in the work he creates
I get into the office around 9AM and check email (and make my daily
coffee – can't miss it). Great. I usually spend some time cleaning up
correspondence between some product owners and our tech leads discussing
new ideas around new product X or feature Y. A quick scan of New Relic and Airbrake reveal that the site's humming along well.
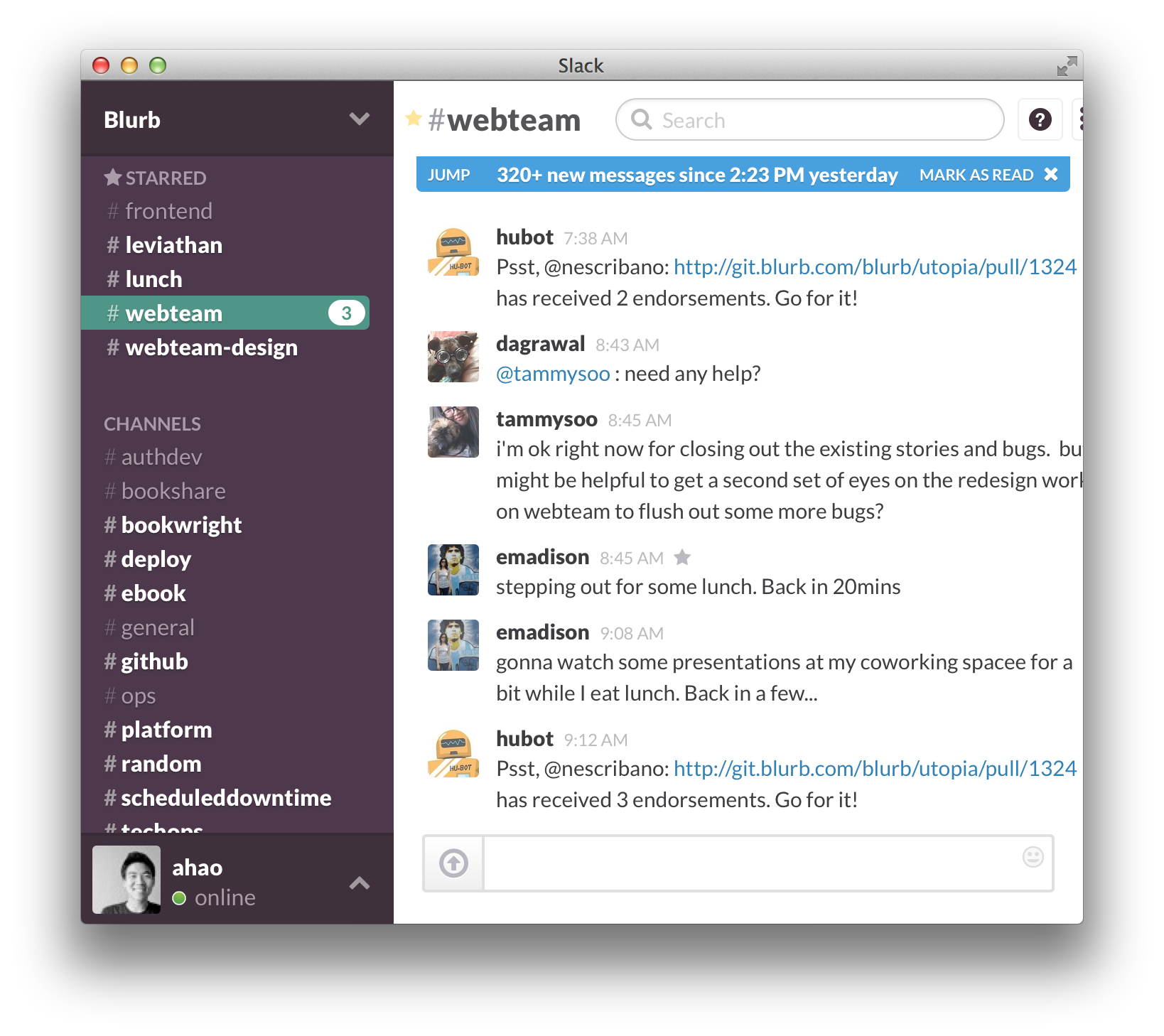
I log into Slack, our central communication hub,
and quickly get a dump of the conversations by our teammates in the
morning and last night. Surprisingly, something as simple as a central
chatroom has helped break down some communication walls in our teams.
Furthermore, having a continual log of team conversations have helped
our remote workers keep abreast of continual updates.
Agile @ Blurb
I log into JIRA and scan the board to check our team status. Looks like
we still have a lot of in-progress stories. I'm currently not assigned
anything.
At our daily standup, Chris, a senior engineer on my team, is working on
story Z. I decide I'm going to ask Chris how he's doing
and see if I can help.
Chris tells me that he needs some help writing a few tests for his
feature, so I pull up a chair and we jump right into it – he implements
the feature, I write the tests. Time passes. We finish our work and we push
our branch up to the Github server for some code review.
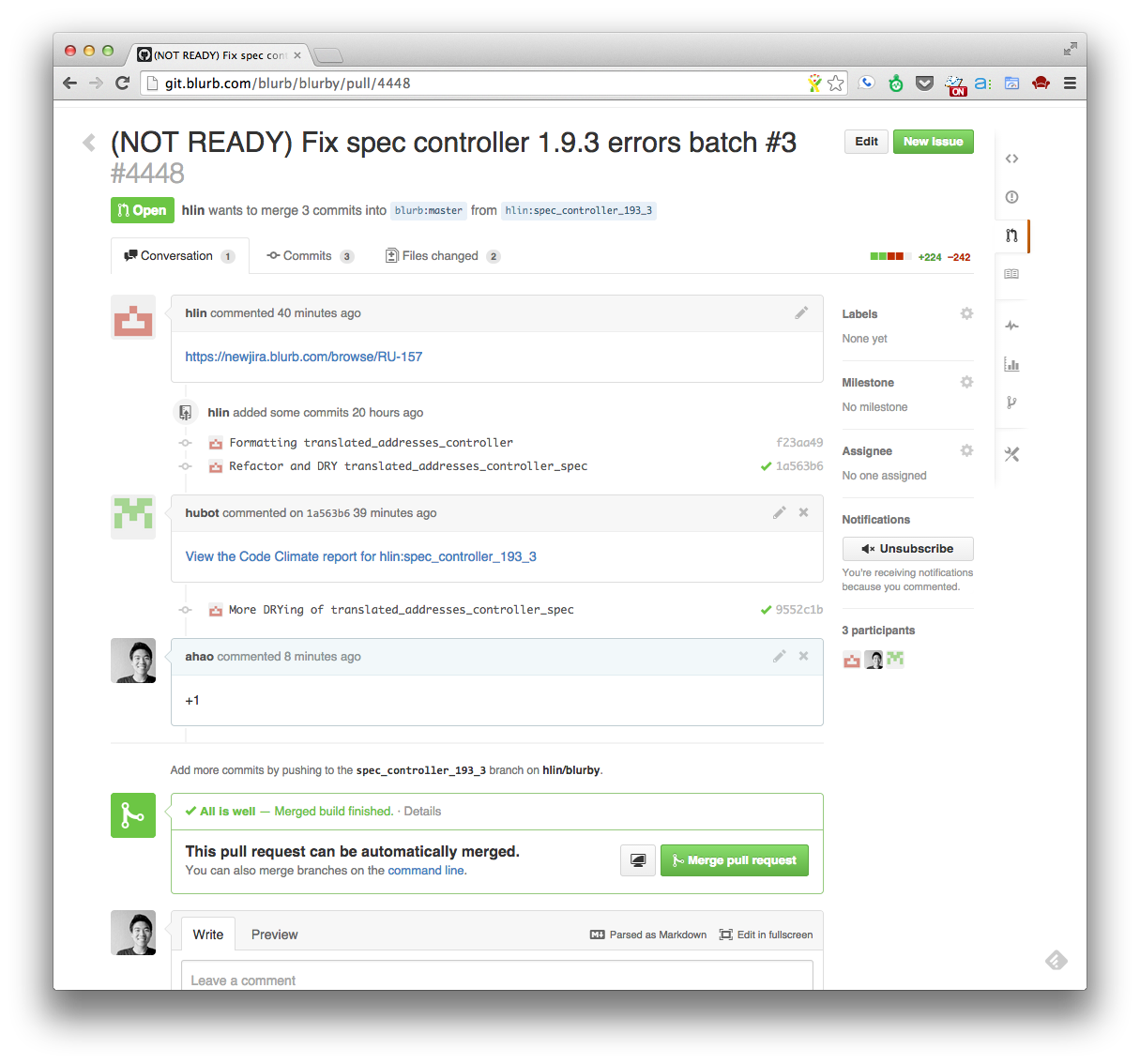
Code reviews
Code review on our team is done via the pull request system – we ping
our teammates on Slack and ask for a code review. The comments begin
flowing in, and we respond.
Simulataneously, we're looking at Code
Climate to give us feedback on how our code
fared against its static analysis tools. Hmm, we seem to have bumped
code complexity a bit in this class, so let's sit down and refactor some
more. We push a change and we ask folks in our chatroom to help give
comments once more.
(Lunch rolls around. We grab some coworkers to stretch our legs and go to lunch at
Senor Sisig, which
is probably the best food truck in the world.)
Our team works on a 2-"+1" code review system. When we make code
changes, we need at least two other people on the team to approve our
code. It sounded a little daunting at first, but it's been a good way to
make sure that the right conversations are happening around the code.
Robots make life better.
Our hubot sits in the chatroom and
tries to be a little helpful. Here, hubot chimes in and lets us know
that two people have given their approvals.
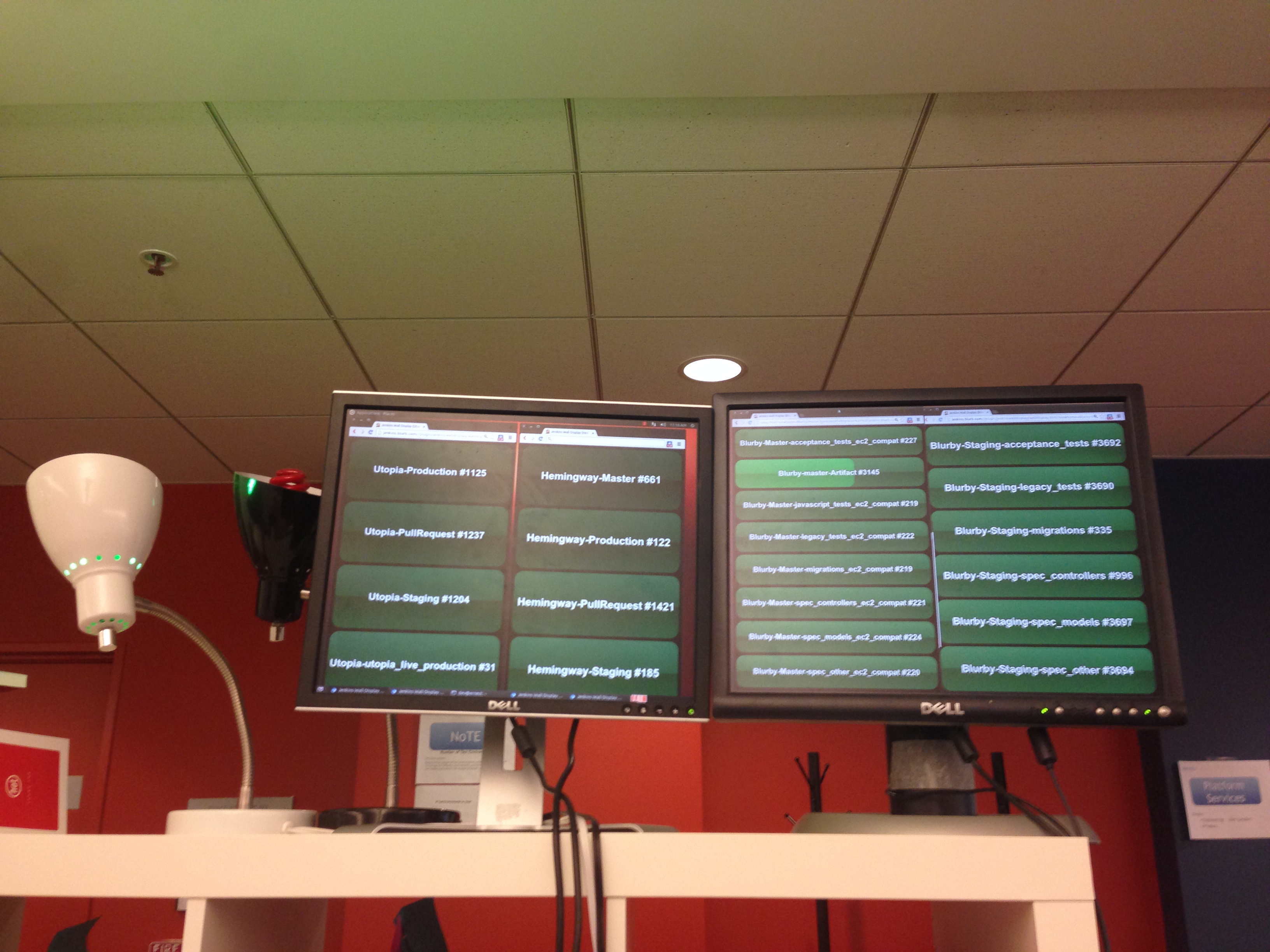
Continous integration @ Blurb
We merge the pull request and wait for Jenkins to run the unit test
build. We keep a big ol' build light on a bunch of build monitors in our work
area. If you break the build, the big red light will radiate waves of
Shame upon you until you fix the build.
Once the build passes, it automatically deploys the app to an internal
staging environment – the whole process happens within 15 minutes.
Sheree, a test engineer on our team, has already run ahead of us and
written some RSpec integration tests prior to our implementation. Chris
has already sat down with Sheree prior to beginning the story and
defined some of the stories and use cases, BDD-style. We work together
to get the integration tests running and working.
All in a day's work.
A big reason I enjoy working here is because our daily development
workflow encourages teamwork and collaboration, and you can get feedback
on your changes very quickly. And we're making it better! Stay tuned as
we continue to write more about our engineering practices.
Andrew is an Engineering Manager on the Web Team. He has long ago
acknowledged the superiority of Senor Sisig burritos and looks forward
to them all week.
Ember's handlebars helpers don't like having too many arguments (it allows you to have one argument and an options hash). It also doesn't like nested calls, such as having one helper that takes the result of another helper as an argument.
A while ago, we added a helper method for i18n-js that allows us to translate things in the view layer. In order to make the helper method handle string interpolation with nested translations (for example: translating "If you want to learn more, click #{here}", and then here is itself a translated link to somewhere), we make the translate helper recognize a special suffix. We called it Key, so any translation key that ends in Key represents a nested translation (such as hereKey for the earlier example).
Then, we translate the key before passing it in for string interpolation as part of the original translation.
We also had some trouble using the message field in ember-validations, as it overwrites i18n and appeared to be setting the message value before we set our i18n-js locale, causing all our error messages to be stuck in english.
We fixed it by changing the message from trying to translate the string to just returning the translation key and changing the view accordingly to handle the translation there instead.
This builds off the sideloading ApplicationSerializer introduced in this article and adapts it to handle JSON objects that don't have "id" as their primary key. Several instances where this might come up are when handling currencies or countries.
If we import this using the previously defined sideloading serializer, we end up with four currencies, each with a generated id, which can quickly start to clutter our store when we start handling dozens or hundreds of prices in multiple different currencies.
In order to fix this, we need to look at the sideloadItem method.
primaryKey in this case is always set to "id", because this in our case refers to the ApplicationSerializer rather than the serializer for item. Ember Data always needs an id for its records, so what we can do instead of letting each currency generate a new one is set the id here based on some other primary key.
At this point, type is the class of the item (App.Currency) and item is the payload of the json, which should look something like this (note that it hasn't been run through the serializer for its class yet):
{ iso_id: "USD", symbol: "$", delimiter: "," }
So what we can do is shove an id into the item before pushing it into the sideload array, by checking to see if the class has a nonstandard primary key that we want to store as the id of the item.
And to set the rawPrimaryKey (raw because we want the key the json gives us, because we haven't yet normalized it to the class's actual ) as a class attribute, we need to reopen the it, as so:
Now, loading the data gives us four prices and two currencies, with the added bonus that comparing the currencies of two prices with the same currency should now work as expected without needing a custom compare method.
Last April, I presented at the Ember NYC meetup
to discuss different approaches for sorting an ArrayController. This is a
short synopsis, you can learn more in the meetup video and slides.
To sort an Ember ArrayController you may have used the included
SortableMixin sortProperties and sortAscending properties. These
are great and work really well for sorting on one property or sorting on
multiple properties all in the same direction. But that's a huge caveat,
SortableMixin does not allow you to sort by multiple properties in different
directions.
For example, suppose you have a list of books you want to display, with the
most recent at the top. Using the SortableMixin, this is done by setting
sortProperties and sortAscending, and then referencing the arrangedContent
property in our template or view:
While sortProperties lets us specify more than one property to order by, you'll notice
sortAscending is a boolean value and gets applied to all properties.
But what if we wanted to sort by the publish date first in descending order,
then by title in ascending order? We're unable to sort in different directions without applying a custom
sort function (which can get cumbersome).
Welcome Ember.computed.sort
The Computed Property Macros have several methods for creating common types
of computed properties. Ember.computed.sort allows us to:
Sort properties by different criteria
Use a custom comparison function when needed
Sort by computed properties
Ember.computed.sort has two parameters:
dependentKey: a reference to the content we're sorting
sortDefinition: either a string referencing the property key containing the sort definition or a custom sort function
In the example below, sortDefinition is the property key propertiesToSortBy,
which is an array of property keys and the corresponding sort direction. By
default, properties are sorted in ascending order, but by appending ":desc" to the
key we can change the sort direction. This allows to specify a different
sort direction for each property:








{kind=link}